Compared with GLM-4.5, GLM-4.6 brings several key improvements:
Longer context window: The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
Superior coding performance: The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
Advanced reasoning: GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
More capable agents: GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
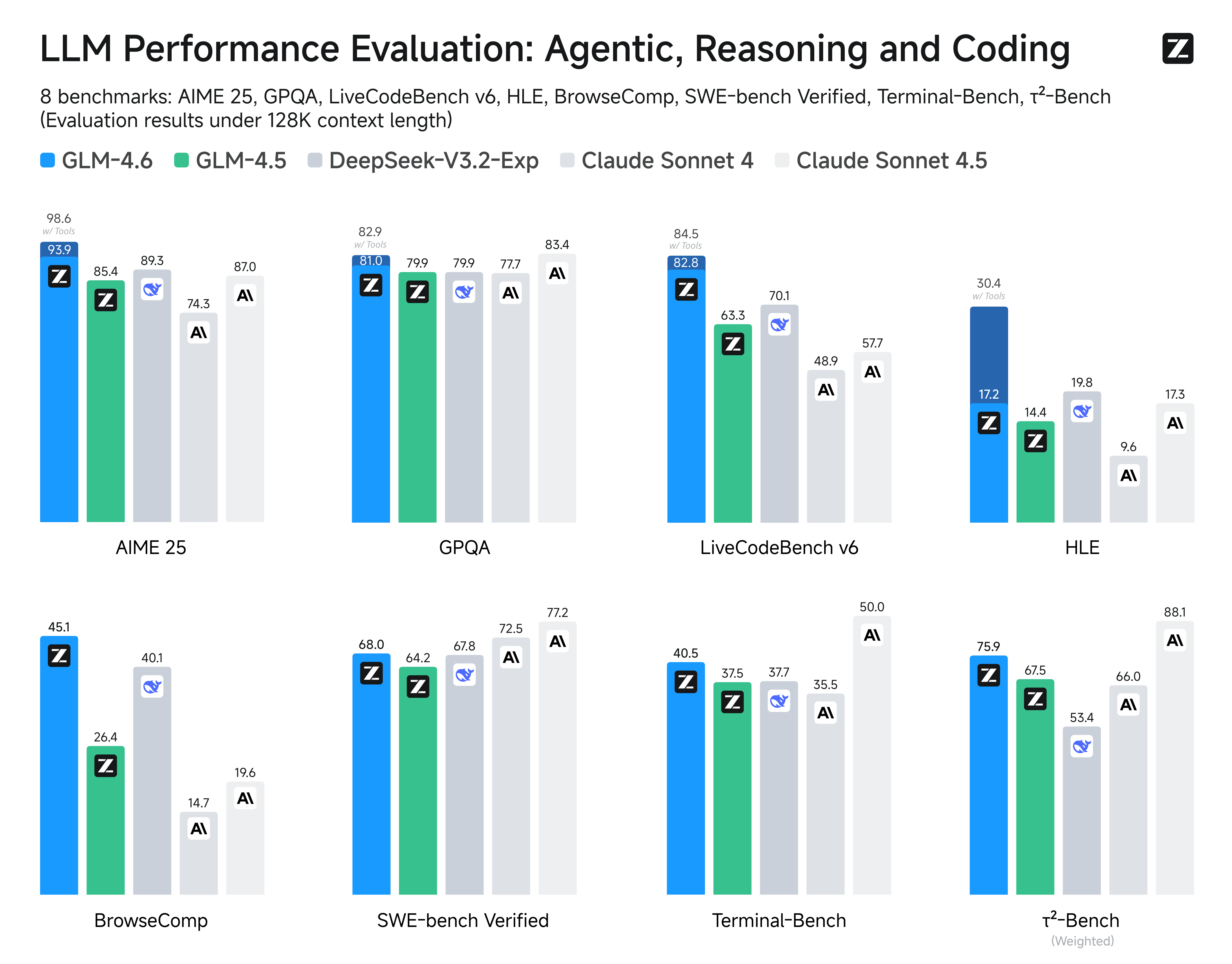
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
Inference
Both GLM-4.5 and GLM-4.6 use the same inference method.
For general evaluations, we recommend using a sampling temperature of 1.0.
For code-related evaluation tasks (such as LCB), it is further recommended to set:
top_p = 0.95
top_k = 40
Evaluation
For tool-integrated reasoning, please refer to this doc.
For search benchmark, we design a specific format for searching toolcall in thinking mode to support search agent, please refer to this. for the detailed template.




# !pip install llama-cpp-python from llama_cpp import Llama llm = Llama.from_pretrained( repo_id="unsloth/GLM-4.6-GGUF", filename="", )